Supervised vs Unsupervised Learning: Complete Guide 2025 | ML Algorithms
Supervised vs Unsupervised Learning ! The world of AI and machine learning continues grow rapidly with both the two types of learning unsupervised and supervised remaining the two main pillars of contemporary data science. With organizations across the world embracing the digital revolution and AI driven strategies Understanding these machine learning techniques is now essential for engineers data scientists and business leaders too.
Machine learning algorithms allow computers to recognize patterns in data without the need for any explicit programming. The main difference between supervised and unsupervised learning is primarily in the ways that the algorithms work with the training data and the outcomes they yield. This guide will explore each of these paradigms thoroughly and helps you determine how to implement each method and ways to enhance their efficacy in real world situations.
Read Also – Top 10 Virtual Reality Devices to Watch in 2025: Ultimate Buyers Guide
Understanding Supervised Learning
What is Supervised Learning?
Supervised Learning is a technique of machine learning in which algorithms are trained by labeled training information. In this model every learning example has input characteristics that are paired with output labels or targets. The algorithm learns how to match inputs to outputs through discovering patterns in the data that is labeled. This allows it to predict of new data which is not previously seen.
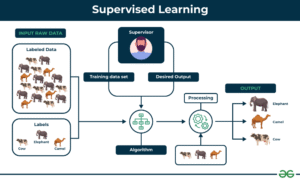
Consider supervised learning to be the process of learning under the guidance of the guidance of a teacher. The algorithm gets feedback regarding its predictions in the process of training which allows it to modify the parameters of its algorithm and increase precision in the course of time. The feedback mechanism differentiates in supervised learning from other methods of machine learning and makes it particularly useful in predictions.
Types of Supervised Learning Algorithms
Classification Algorithms
The classification tasks are based on the prediction of categorical categories or classes. Most commonly classification algorithms are decisions trees logistic regression random forests as well as support vector machines non naive Bayes classifiers K nearest Neighbors as well as neural networks. The supervised learning algorithms excel in areas such as detection of spam image recognition diagnostics medical sentiment analysis as well as fraud detection.
Binary classification can be described as having two possibilities of outcomes whereas multi class classification can handle multiple types of categories. Innovative techniques such as the ensemble method use multiple classifiers in order to increase predictability and robustness of models.
Regression Algorithms
Regression analysis is a method of predicting constant numerical numbers not categorical categories that are discrete. Most popular techniques for regression include the linear and polynomial regression the ridge regression lasso regression elastic net and the support vector regression. These are the most effective algorithms in forecasting and estimate of demand price prediction and the analysis of trends.
Time series forecasting is an application for regression that is specialized that allows predictions made based on the temporal pattern. Recurrent neural networks as well as long term short term memory networks have transformed predictions of time series.
How Supervised Learning Works
The process of learning supervised has a logical workflow. Data scientists first collect and create training datasets with labels to ensure data accuracy as well as representativeness. The process of feature engineering converts the unstructured data into relevant input variables which algorithms can be able to process efficiently.
In the course of model development it analyzes the relation between input characteristics as well as output label. The algorithm adjusts its internal parameters in order to reduce the probability of errors in prediction which are measured by loss functions and cost functions. The most commonly used optimization methods include gradient descent stochastic gradient and adaptive rate of learning techniques.
Model evaluation employs separate validation sets that evaluate the models effectiveness on data that is not seen. Measures such as accuracy precision and recall F1 score and mean squared error and R squared coefficients help to quantify the efficiency of models. Cross validation methods provide reliable estimations of performance using models that are tested on a variety of different data sets.
Advantages of Supervised Learning
Supervised learning has a variety of compelling advantages. Its use of data that is labeled permits precise measurement of performance as well as simple modeling. Accuracy metrics are transparent benchmarks that allow for comparison of the various architectures and algorithms.
They are able to make particular predictions when enough instances with labels are available. Feedback mechanisms throughout training permits the continuous improvement of and fine tuning. Transfer learning allows you to leverage pre trained models to perform similar jobs thus reducing the duration and the need for data.
Supervised algorithms for learning have established performance in a wide range of fields and extensive research that supports methods for implementing best practices. The algorithms predictable nature makes it ideal for environments in which the reliability of an environment is essential.
Challenges and Limitations
Although it has its advantages it faces major problems. Labeling training data for supervised learning is costly and lengthy usually needing domain specific expertise to ensure accurate annotation. Labeling of data is expensive and can prevent supervision for those that have limited funds.
The process of overfitting happens when models remember the training information rather than learn universal patterns. This leads to excellent results in training but low testing accuracy. Dropout techniques regularization and the early stopping of tests help to reduce the risk of overfitting.
The problem of class imbalance is when certain classes appear more often than others in the training data. The bias could make models prefer majorities which can lead to inadequate predictions of minority groups. Methods of sampling weighted loss functions and artificial data generation are used to address imbalances in class.
Supervised models are challenged by the shift in distributions of testing data differs from distributions of data. This decreases the reliability of prediction in environments that are dynamic. Monitoring and continuous retraining of models helps to maintain the accuracy throughout time.
Real World Applications of Supervised Learning
Healthcare and Medical Diagnosis
Supervised learning revolutionizes healthcare by the prediction of disease and medical imaging analysis and forecasting of patient outcomes. Convolutional neural networks identify anomalies in X rays MRI scans and CT scans that have radiologist level accuracy. The predictive models help identify those who are at risk of developing conditions such as heart disease diabetes as well as cancer.
Electronic health records can be supervised by algorithms to suggest personalized treatments. Natural language processing gathers knowledge from medical notes enhancing the diagnostic system. Applications for drug discovery employ the process of supervised learning to identify the properties of molecular molecules and their effects on treatment.
Financial Services and Fintech
Financial institutions and banks use supervision for credit scoring and loan approval as well as the detection of fraud as well as risk evaluation. Models for classification identify transactions that are suspicious immediately and prevent fraud. Regression algorithms can predict the price of stocks as well as portfolio returns and volatility in the market.
Algorithmic trading systems rely on supervising learning in order to perform automated trades in accordance with the markets conditions. The prediction of customer churn helps keep loyal customers by providing targeted intervention. Anti money laundering tools flag criminal financial activity for investigation.
E commerce and Retail
Online retailers use the power of supervised learning to provide suggestions for products and dynamic pricing. It also aids in forecasting demand and segmentation. Recommendation engines study purchase histories as well as browsing habits to recommend suitable items. Computer vision models provide visually based search which allows buyers to search for items by uploading pictures.
The systems for inventory management predict optimal stocks which reduces waste and also avoiding the possibility of stock outs. Analyzing customer feedback aids in product enhancement as well as marketing strategies. The algorithms for personalization tailor web experiences according to the individuals preferences.
Autonomous Vehicles
Autonomous cars heavily rely on supervised learning in order to assist with tracking objects lane recognition and traffic sign recognition as well as pedestrian detection. Deep learning algorithms analyze the sensor data of cameras lidar and radar to better understand the surrounding driving conditions. Semantic segmentation algorithms categorize each pixel of cameras camera feeds.
Path planning systems determine optimal routes based on traffic patterns and road conditions. The driver assistance functions like adaptive cruise control as well as automated emergency braking employs supervised learning to increase the safety.
Understanding Unsupervised Learning
What is Unsupervised Learning?
Unsupervised learning uncovers the hidden patterns and structures that exist within unlabeled data that do not fall into any predefined output classifications. The algorithms analyze data on their own and can identify relationships similarities and asymmetry without assistance. There is no labeling to distinguish unsupervised learning from its counterpart supervised.
The way we learn is similar to human learning through exploration and observation. Kids learn about the world around them by discovering patterns and groups of identical objects with no explicit instructions. Similar to unsupervised algorithms that reveal the structure of data through the analysis of statistical data and mathematical optimization.
Types of Unsupervised Learning Algorithms
Clustering Algorithms
Clustering clusters similar data points according to feature similarity. K means Clustering splits data into clusters of k distinct groups to reduce the variance within clusters. Hierarchical clustering creates tree like structures with nested groups at various level of granularity.
DBSCAN detects clusters with arbitrary forms while also detecting anomalies. Gaussian mixture models rely on the assumption that data is derived from multiple probability distributions. Mean shift clustering identifies large areas in feature space without defining the numbers of clusters prior to analysis.
Spectral clustering employs graph theory to create complicated patterns recognition. Applications of clustering include segmentation of customers documents document organization image segmentation as well as an analysis of expression in genes.
Dimensionality Reduction
Techniques for reducing dimension compresses high dimensional data into less dimensional representations without sacrificing the vital information. Principal component analysis helps identify the orthogonal directions with maximum variance and creates features that are not correlated.
T distributed stochastic neighbors embedding displays the high dimensional information in three or two dimensions. It reveals cluster patterns. Autoencoders employ neural networks to acquire encoder decoder structures to compress representations.
Singular Value Decomposition breaks down matrixes into components that allow data compression and noise reduction. Independent component analysis is a way to separate the mixed signals into statistically distinct sources.
Association Rule Learning
Association rule mining reveals interesting connections between variables within huge databases. Apriori algorithm is able to identify frequent itemsets and then generates associations rules. The FP growth algorithm effectively mines for common patterns with no candidate generation.
Market basket analysis can reveal the most popular combinations of products and forming the basis for cross selling strategies. Sequential pattern mining uncovers patterns in time based data.
Anomaly Detection
Anomaly detection is a way to identify patterns that differ significantly from typical behaviour. Isolation forests can detect outliers by randomly parting the data. One class SVM discovers boundaries for typical data and points.
Local outlier factors measure variations in local density that can be used to detect irregularities. Statistics like Z score and interquartile range identify observations that are that are not typical. The detection of anomalies protects against cybercrime fraud as well as equipment malfunctions and the possibility of quality issues.
How Unsupervised Learning Works
Unsupervised learning algorithms analyse structures of data through the use of mathematical optimization as well as statistical inference. They establish objective measures of quality of the datas organization and tweak parameters repeatedly to enhance the metrics they are analyzing.
Clustering algorithms limit distances between clusters and maximize the distance between clusters. The cluster centers are initialized by random selection or using heuristics. They afterwards they assign data points to them and update them until they achieve convergence.
Methods for reducing dimension increase variance preservation or reduce the error in reconstruction when transferring data to smaller dimensions. These algorithms are iterative and converge towards the most optimal projections using eigenvalue decomposition as well as gradient based optimization.
Unsupervised learning demands careful interpretation of the results. Knowledge of the domain helps confirm found patterns and differentiate real structures from their artifacts. Visualization tools aid understanding complicated patterns.
Advantages of Unsupervised Learning
Unsupervised learning has unique benefits when it comes to data exploration as well as pattern recognition. It does not require labels on data and eliminates costly annotation tasks. It is therefore feasible to use unsupervised techniques when labeling data is either impossible or not practical.
These algorithms uncover unexpected patterns and relations which human analysts may overlook. They process unlabeled data on a the scale of massive databases and can process them quickly. Unsupervised learning can be an essential preprocessing process and can be used to create features that are suitable for later task that require supervision.
The process of clustering and reduction in dimensionality simplifies complicated data and make it simpler to comprehend and easier to manage. Anomaly detection detects unusual anomalies without the need for labeled examples for every type of anomaly. Its versatility allows for imaginative applications across a range of fields.
Challenges and Limitations
Unsupervised learning poses unique challenges. With no ground truth labels the evaluation of algorithm performance is subjective. Different metrics can suggest differing best solutions. This requires cautious verification.
Understanding results requires expertise in the domain to discern important patterns from the noise. The clusters might not be correlated with sensible or helpful classifications. Selection of parameters for example the size of clusters has a significant impact on results but is not based on any objective standards.
The algorithms may be able to converge on local or global optimal strategies. Many runs using different initializations aid in identifying stable patterns. The computational complexity may be very extremely high when large data sets have numerous dimensions.
Unsupervised techniques arent as effective in making precise predictions when than supervised methods. They are more adept at exploring than regression or classification tasks. Combining learning with supervised and unsupervised is often more effective over either.
Real World Applications of Unsupervised Learning
Customer Analytics and Marketing
Unsupervised learning is a method used by businesses for customer segmentation. It helps in identifying distinct groups that share similar features and behaviours. Marketers create campaigns that are tailored to the specific segment of customers increasing their relevance and efficiency of conversion. Clustering algorithms categorize customers based on purchasing patterns demographics as well as engagement levels.
Market basket analysis uncovers the potential for cross selling by identifying products often purchased in conjunction. Recommendation systems employ filters that are collaborative to recommend products that match similar preference. The reduction in dimension makes it easier for customers to use their data to make it easier for analysis and visualization.
Natural Language Processing
Topic modeling algorithms such as latent Dirichlet allocation can identify themes within documents that do not have categories predefined. These techniques organize large text corpora enabling efficient information retrieval. Word embeddings such as Word2Vec and GloVe discover semantic connections between words via unsupervised training.
Document clustering is a method of combining similar text to help organize them and make it easier for summarization. Machine translation that is unsupervised and learned by analyzing monolingual corpora. Models of language that are trained using unlabeled text are the basis of modern natural language processing system.
Computer Vision and Image Processing
Image segmentation separates images into distinct regions with no labeled examples. These algorithms cluster pixels according to their color and texture characteristics. Unsupervised feature learning provides valuable image representations that can be used for further jobs.
Generative adversarial networks can create real world synthetic images by way of non supervised learning. Autoencoders compress images to remove any noise. Unsupervised object discovery detects the most salient zones without bounding boxes annotations.
Cybersecurity and Fraud Detection
Anomaly detection safeguards the system by spotting abnormal network activity such as user behavior or transactions patterns. Unsupervised algorithms adjust to changing threat types without needing specific examples for each kind of attack. The clustering of security incidents in a similar way to make it easier to analyze.
Intrusion detection systems employ unsupervised training to base regular activity and detect the deviations. Fraud detection flags suspicious transactions that are not typical. Analysis of malware uncovers novel malware variants by using the process of behavioral clustering.
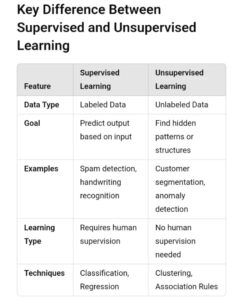
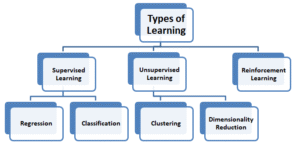
Supervised vs Unsupervised Learning: Key Differences
Data Requirements
The main difference is in the requirements for data. The supervised learning process requires labeled data that contain the input characteristics as well as outputs. Making these labels is a process that requires patience experience and the right the resources. Costs for data annotation often decide the viability of projects.
Unsupervised learning is based on unlabeled data analyzing information with no defined categories or targets. This is a good choice in situations where labeling is not feasible such as investigating new areas or analysing large amounts of data. A large amount of data that is not labeled can make unsupervised techniques extremely adaptable.
Learning Objectives
Supervised Learning aims to teach an algorithm for mapping inputs and outputs that can be used to make forecasts on data that is new. The goal is simple: reduce the error in prediction on untested cases. The success metrics can be defined by accuracy as well as precision recall as well as similar measures.
Unsupervised learning aims to comprehend data structure and reveal the hidden patterns. Objectives include grouping similar items reducing dimensionality or finding anomalies. It is difficult to quantify success and often requires qualitative evaluation and interpretation of the domain.
Algorithm Complexity and Interpretability
The algorithms that are supervised range from basic linear models to more complex neural networks. The simpler models such as logistic regression are highly interpretable and clearly show how the factors affect the predictions. Advanced models such as deep learning improve accuracy but they sacrifice the ability to interpret.
Unsupervised algorithms differ in their complexity. K means clustering is both intuitive and simple to understand While deep autoencoders require complicated designs. Unsupervised analysis requires an understanding of the algorithms mechanics as well as the context of the domain.
Computational Resources
The training of supervised models in huge datasets labeled with data requires substantial computational power specifically for applications that use deep learning. Graphics processing units as well as Tensor processing units speed up learning. The complexity of the model and the size of the dataset will determine the amount of resources needed.
Unsupervised learnings computational demands differ depending on the algorithm employed and the size of data. Certain clustering techniques are linearly scalable with the size of data and other methods require cubic or quadratic time. Reduced dimension on data with high dimensions is often computationally demanding. The algorithm may require many runs through the data before achieving convergence.
Use Cases and Applications
Supervised learning is most effective when clearly defined predictions are made and labelled training data for the trainee is accessible. Regression and classification tasks that have clear outcomes can be supervised. Examples include spam detection the diagnosis of diseases forecasting prices and image recognition
Unsupervised learning can be seen in the exploration analysis data preprocessing as well as situations that do not have the labeled information. The clustering process the reduction of dimensionality and detection of anomalies leverage methods that are not supervised. Application areas include customer segmentation topics discovery feature learning and identifying outliers.
Evaluation Metrics
Supervised learning evaluation is based on an objective measure to compare the predictions with the actual classification. Measures of classification are precision accuracy and recall. F1 scores ROC curve and the AUC. Regression metrics are mean squared error the roots mean squared error mean absolute error as well as R squared.
Evaluation of unsupervised learning is more subjective. Quality metrics for clustering include silhouette coefficients Davies Bouldin Index and the Calinski Harabasz Index. They measure the cohesion of clusters and separation but they dont provide a guarantee of meaningful clusters. Inspection of the domain and validation is often required.